Natural Language Processing: Tokenize and Plot

Words matter.
Import Packages
#Import Packages
import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter
import nltk
Generate a “Bag-Of-Words”
#Extracts contents of a file, returns a bag of words(count of each word)
def count_words(document):
#Load target File as 'document' to 'raw_file'
raw_file = open(document).read()
#Tokenize all words in 'raw_file' using word_tokenize()
token_list = nltk.tokenize.word_tokenize(raw_file)
#Convert each item in token list to lower_case list
lowercase_tokens = [each.lower() for each in token_list if each.isalpha()]
#Create list of each word and associated count
bag_Of_Words = Counter(lowercase_tokens)
return bag_Of_Words
Check our Bag Of Words
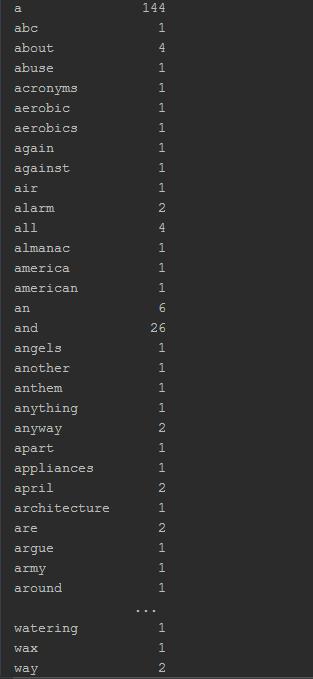
Series
word_series = pd.Series(count_words(your_doc))
Describe
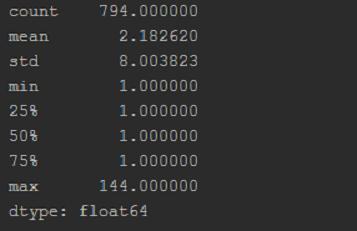
print(word_series.describe())
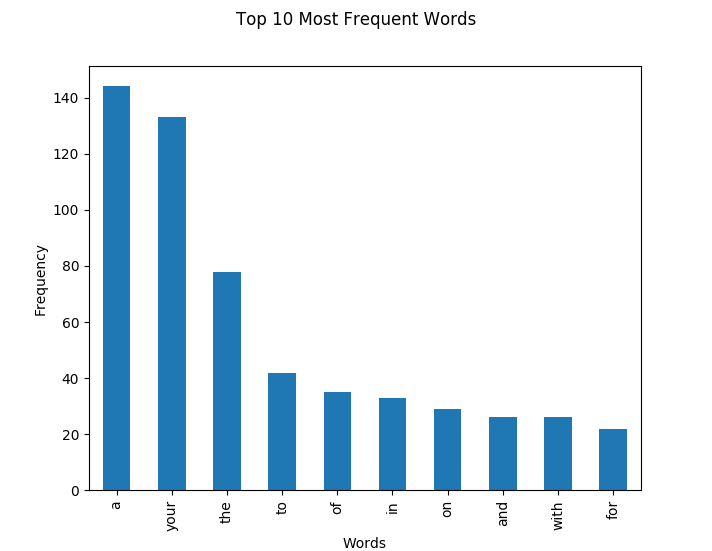
Plotting Counts
#Given a particular bag of words, desired counts, creates a dataframe,
#resets index, plots counts
def plot_counts(bag_of_words, amount):
#Convert bag_of_words array to a dataframe defined by top 'amount'
#ex '10' for top 10 words in array
df = pd.DataFrame(bag_of_words.most_common(amount))
#Sets index to column '0', which holds the string value for each entry,
#col '1' contains the count
df.set_index(0,drop=True,inplace=True)
#Define a bar plot
df.plot(kind="bar", legend = False)
plt.xlabel("Words")
plt.ylabel("Frequency")
plt.suptitle("Top " + str(amount)+ " Most Frequent Words")
#Display plot
plt.show()
Code Summary
Below is a class version of the above code for you to play with, note that you’ll need to specify your specific file path where I’ve written ‘your_document’ in the parameter for run.count_words(your_document)
#Import Packages
import pandas as pd
import matplotlib.pyplot as plt
import nltk
from collections import Counter
#nltk.download('punkt') - Use if error raised at runtime
class BagOfWordsTokenizer(object):
#Extracts contents of a file, returns a bag of words(count of each word)
def count_words(self, document):
#Load target File as 'document' to 'raw_file'
raw_file = open(document).read()
#Tokenize all words in 'raw_file' using word_tokenize()
token_list = nltk.tokenize.word_tokenize(raw_file)
#Convert each item in token list to lower_case list
lowercase_tokens = [each.lower() for each in token_list if each.isalpha()]
#Create list of each word and associated count
bag_Of_Words = Counter(lowercase_tokens)
return bag_Of_Words
#Given a particular bag of words, desired counts, creates a
#dataframe, resets index, plots counts
def plot_counts(self, bag_of_words, amount):
#Convert bag_of_words array to a dataframe defined by top 'amount'
#ex '10' for top 10 words in array
df = pd.DataFrame(bag_of_words.most_common(amount))
#Sets index to column '0', which holds the string value for
#each entry, col '1' contains the count
df.set_index(0,drop=True,inplace=True)
#Define a bar plot
df.plot(kind="bar")
#Display plot
plt.show()
if __name__ == "__main__":
run = BagOfWordsTokenizer()
wordBag = run.count_words(your_document)
howMany = input(print("How many of the top words would you like to be displayed?"))
run.plot_counts(wordBag, howMany)
Written on March 21, 2018